Preface
This document was originally written to describe the very successful version 2 SNF engine. The core pattern matching engine in Version 3 of SNF is an extension of this technology - in fact more than 80% of the code is identical.
While this document's metrics may be a little bit out of date, the core concepts are still correct. Most of the extensions and enhancements we've added to the SNF V2 pattern matching engine are described elsewhere in our site. We will be developing additional materials as we continue to develop our documentation and our software.
Contents
Overview
Message Sniffer is a content based anti-spam tool that uses an advanced pattern matching engine to filter email based primarily on it's content. The pattern matching engine, which is derived from cellular automata research, is capable of applying many thousands of heuristic rules to each message rapidly and efficiently. While the rule base for this application is designed to capture spam, the underlying technology is actually designed to locate patterns of any type in a stream of data.
Message Sniffer is typically installed on an email server using some kind of "external agent" hook. Using this hook, the server will pass a message to Message Sniffer and wait for a result code that indicates how the message was categorized. A zero result typically indicates a "clean" or "white-listed" message, while a non-zero result typically indicates some kind of spam. The server software can then decide what to do with the message based on the result.
On advanced email platforms the server software may provide a wide variety of options for redirecting, tagging, rejecting, or holding messages that are recognized as spam by Message Sniffer. Some of these provide the ability to take different actions based on the different result codes produced by Message Sniffer. The most flexible systems typically also provide an ability to combine the results from a number of filtering utilities and tests (such as DNS based black lists) as well as an ability to apply different filtering policies for distinct domains, and individual users. (IMail with Declude Junkmail Pro is a good example of this kind of system.)
On many systems, such as Postfix and Vopmail, the options for processing messages are determined by scripts that call the Message Sniffer utility and process the message based on that result before returning to the server software. In these cases a high level of sophistication is possible - limited generally by the scripting skills of the email administrator.
Now that the Message Sniffer V2 engine has been released in an open source distribution, we can expect to see systems with very sophisticated implementations and vastly improved performance. One of the best opportunities for improvement is to implement the Message Sniffer engine as a component of either email server (MTA/MDA) or anti-spam software.
When operating as part of a daemon (or service) the Message Sniffer engine can keep it's rulebase(s) loaded at all times and may process messages without ever having those messages written to the hard drive. In contrast, the sniffer2.exe utility must load the rule base file each time a new message is scanned. Loading the rulebase can account for more than 90% of the total processing time in some cases.
Performance
Typically 1/2 to 2/3 of the processing time in milliseconds is attributable to loading the rulebase file. Total message scan times (including all operations) average 180ms per message on moderate computing equipment (P3/800Mhz, 512Mram, 7200rpm IDE drive, Win NT, system handling 1000 msgs/hr w/ IMAP, POP3, & HTML access to user accounts). Typical rulebase file size ~1.2Mbytes containing 7000 active heuristics. Generalized real-time performance metrics (combined from a number of our client systems) are available on our website in the Live Data section.
Additionally, the act of writing a message to disk, reading it again for a message scan, and then moving or copying the message yet again to get it to it's final destination can represent a significant load on busy email servers. A better approach would be to evaluate the message as it is received and determine it's disposition before ever writing the message to a hard drive.
That said, the version 2 implementation of Message Sniffer is intended to take advantage of a few of things that are common in many email systems today:
- For flexibility, many systems implement some mechanism that allows an external program to evaluate an email message from the hard drive. Implementing Message Sniffer as a command line utility makes this integration process very simple.
- Many email systems that provide spam filtering also provide virus filtering. Most of the virus filtering systems that are available are implemented as file scanners. In order to utilize these scanners the message must be written to the hard drive. As a result, Message Sniffer can typically "piggy back" on this process without causing the message to be written to the hard drive more than once.
Architecture
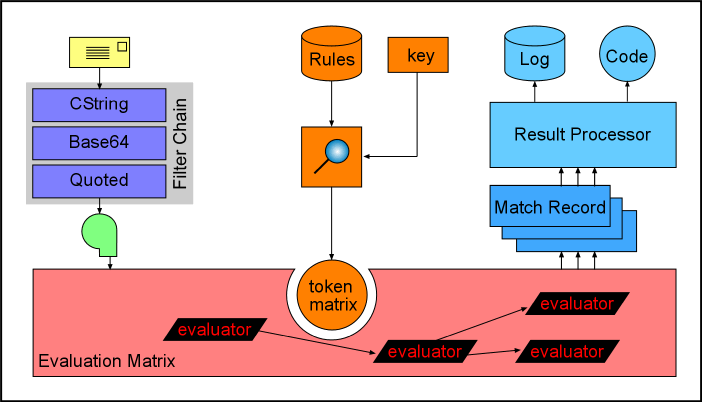
Architecturally, the Message Sniffer utility (sniffer2.exe) is organized like a pipeline. The message file is fed in one end of the pipe, filtered to expose important features and protect the mechanism, and then pumped into the pattern matching engine. The pattern matching engine identifies all of the features it can recognize and converts the message into a collection of pattern match records. The pattern match records are interpreted by the result processor and delivered at the output end of the pipe as a result code and a log file.
The following diagram illustrates this architecture.
Loading the Message
The first thing Message Sniffer does to a message is load the first 32 Kbytes into a memory buffer. This is done as a single step so that the underlying operating system can be extremely efficient about the process. Typically not more than 32K of a message is scanned by Message Sniffer since larger messages are almost never spam.
Earlier versions of Message Sniffer would read each byte of the message as it was needed. This method simply attached an input stream to the front of the Filter Chain. This mechanism is still useful in some cases but there is a performance penalty due to the increased number of system calls that are made by the program.
Note: There is an experimental development program underway which allows the Message Sniffer engine to be integrated with DNews NNTP servers. This implementation requires that messages are sent to the utility through a standard I/O pipe and that the utility remains live throughout the active life of the service. Although it is clear that the rulebase for filtering NNTP traffic is somewhat different than that for SMTP messages, to date, the prototype has performed extremely well in all tests.
Filter Chain
The Filter Chain segment of the pipeline is implemented as a sequence of interlocking modules. Each module generally has an active and inactive mode. In the active mode, a module inserts itself into the byte stream and performs the operation it is designed for. In the inactive mode a module becomes "transparent" so that the bytes simply pass through it. When a module is in an inactive mode it will also monitor the byte stream for an indication that it must become active.
In general, filter chain modules are designed to be strung together in any order that makes sense for a given application. Modules are also intended to be implemented as finite state machines so that they are highly efficient.
In the Message Sniffer V2 engine, there are four filter chain modules. Two of these modules provide a connection to the input for the filter chain. These are FilterChainInput, which is designed to take input from an InputStream object, and FilterChainCString which is designed to take input from a null terminated buffer. The sniffer2.exe utility implements the latter.
Next, the FilterChainBase64 module monitors the byte stream for any Base64 encoded MIME segments. When a segment is detected the module becomes active and decodes the segment. The byte stream pulled from this module therefore contains either normal text or decoded Base64 data alternately.
Next, the FilterChainQuotedPrintable module monitors the byte stream for quoted printable encoding. As with the Base64 module the QuotedPrintable module automatically decodes any message data it finds. The reason this module is included after the Base64 module is that spammers frequently use Quoted Printable encoding to obfuscate portions of their messages. Often this obfuscation takes place within segments that were Base64 encoded.
Later versions of Message Sniffer will include filter chain modules to emit special features about each message and to reprocess html segments and html based obfuscation techniques. The combination of these functions will have the effect of enhancing the "vision" of the pattern matching engine. It will be as if the pattern matching engine were looking through an advanced "heads up display" that shows features about the message that could not normally be determined by pattern matching algorithms.
For example, one of the enhancements will be the ability to apply certain DNS based black lists and other external tests to a message before scanning it for patterns. The result will be that the engine will discover and recognize patterns not only in the message but also patterns of external test responses. Since these features will all be integrated into a single byte stream before the pattern matching engine is activated the system will be able to also recognize patterns that combine external and internal features - such as matching specific keyword combinations with a particular DNSbl response.
Rulebase File
The rulebase file contains a partially encrypted token matrix image that is binary compatible with Intel processors (little-endian). Each rulebase file is named for a specific license ID. The sniffer2.exe utility is renamed (branded) to match the license ID also. Typical rulebase files are just over 1Mb in size and typically represent between 6000 and 10000 heuristics. The beginning and end of the file are encrypted using the Mangler Stream Encryption algorithm. The encryption is added to protect licensed rulebase files from tampering and decompilation and to protect the integrity of the file - specifically, if a partial download occurs, then the encryption will be broken and the rulebase file will not authenticate.
In version 2, the rulebase file is only partially encrypted. Primarily this is a performance related decision. Since the rulebase file is loaded each time a message is scanned, there is a significant performance penalty associated with encrypting the entire file. The partially encrypted file provides a good deal of security since the most critical elements of the token matrix are encrypted. Partial encryption is also effective against the vast majority of download failures - those which result in partially downloaded files.
It is possible that later versions of Message Sniffer may compress and then fully encrypt the rulebase files. This will be practical once daemon based implementations are the norm since rulebase files will not be reloaded frequently. On the other hand, there is some debate that compatibility with Version 2 should be maintained to ensure that the possibility of technical problems is minimized and so that even daemon based utilities might be implemented in a mixed-use scenario (where the same rulebase can be effectively used in a daemon or in a command line utility).
Authentication Key
Each license ID is associated with a specific authentication key. The license ID is an 8 character sequence consisting of the letters a-z and the digits 0-9. The authentication key is a 16 character sequence consisting of the same characters. Both the license ID and authentication key are generated at random and are both unique for each registered license.
Taken together, the license ID and authentication key form the basis of a secret key for the encryption mechanism. Message Sniffer rulebase files are encrypted using the Mangler Stream Encryption algorithm. This algorithm uses the plaintext (in this case segments of a rulebase file) to modulate the output of a pair of synchronized chaos engines (secure random number generators). In addition to being extremely fast and secure, this algorithm allows us to use a simple constant string at the end of the rulebase file to detect any errors in the encrypted portions of the file (much like a CRC). The chaos engines of the Mangler algorithm are extremely sensitive to change and diverge wildly when any bit in the stream is changed. As a result any single bit error in an encrypted segment will force the remainder of the decryption process to become randomized.
Before the rulebase file is encrypted, license ID is added to the end of the rulebase. When validating the rulebase file the beginning and ending segments of the file are decrypted. Then as a check the decrypted license ID is read from the end of the decrypted file. If the ID matches the name of the rulebase file then the decryption was successful indicating that the rulebase file is essentially intact. (unencrypted portions of the file are not validated).
Evaluation Matrix
The evaluation matrix is the functional shell of the pattern matching engine. The heart of that engine is the token matrix which is delivered by the rulebase file. Within the evaluation matrix, cellular automata called evaluators will grow, live, die, and detect patterns in the data presented to the engine.
A separate paper will describe the details and evolution of the pattern matching engine as that topic is beyond the scope of this document. However a general theory of operations is as follows:
The token matrix shapes an environment within the evaluation matrix. The evaluation matrix then becomes home for a collection of interactive creatures (cellular automata) called evaluators. Before each new byte of data is pumped into the evaluation matrix a new evaluator (creature) is created to live in the matrix. Each new byte that is pumped in alters the environment of the evaluation matrix. A good way to visualize this is to say that the "weather" changes each time a new byte is pumped in.
All of the creatures in the evaluation matrix react to the new "change in the weather" according to where they are in the matrix and the other creatures that are around them. Some of the creatures will eventually find their way to special gateways in the matrix that represent the end of a "known pattern".
Match Records
Creatures that reach the end of a "known pattern" are turned into match records and stored in the evaluation matrix. A match record summarizes the life story of a creature that made it out of the matrix. This information includes the index and endex of the pattern and the "name" of the gateway that the creature reached at the end of the pattern.
The index and endex represent the byte positions of the beginning and end of the matched pattern respectively. The "name" of the gateway is an integer value associated with a pattern rule in the token matrix. We use a mathematical trick to encode the matching symbol and rule ID into this "name" when we encode the rulebase.
Result Processor
After a complete message has been pumped into the matrix there will be a collection of match records that describe all of the patterns that were recognized by the engine. Any other creatures in the evaluation matrix will be discarded.
Message Sniffer V2 evaluates all of the match results in a very simple way. The first rule that is matched with the lowest symbol value is selected as the final result of the engine. This represents a simple priority scheme for the rule groups and ensures that white rule symbols (zero) will always win out over any black rule symbols. Rulebases can be customized and renumbered so that the ordering of the rule groups fits the needs of each specific user.
All of the match results are written to the log file, one result per line, along with an additional line indicating the final result that was selected. The format of the log file is designed to make it easy to import into a database. In order for each line to represent a single record some of the information from a message scan is duplicated across each line. For example, the datetime stamp, license ID, message file name, setup time, scan time, and scan depth are all duplicated in each line.
Later versions of the Message Sniffer engine will use a binary log format and will provide a utility to convert the binary log into formats that are suitable for import to a database.